
Building Custom DePIN GPU Clusters via gpumarketdepin API Integration

Decentralized Physical Infrastructure Networks (DePIN) have transformed GPU access, letting developers assemble bespoke clusters without upfront hardware investments. Platforms like gpumarketdepin. com lead this shift, mirroring io. net’s model of pooling over 30,000 GPUs from data centers and miners for AI workloads at up to 70% less than AWS. This gpumarketdepin API integration empowers you to orchestrate DePIN GPU cluster builds dynamically, scaling compute for training models or rendering at unprecedented efficiency.


io. net’s success on Solana underscores the viability: their peer-to-peer marketplace delivers real-time GPU rentals for batch inference and parallel training. Yet, as demand surges in 2026, generic clouds fall short. Custom clusters via decentralized compute API 2026 standards address this, aggregating resources from Vast. ai, Oracle Cloud, and beyond with instant DNS provisioning. Aethir’s 4,000 and H100 GPUs exemplify the scale, proving distributed networks rival centralized giants.
Decoding the gpumarketdepin API Architecture
The gpumarketdepin API stands out for its precision-engineered endpoints, designed for seamless io. net API custom clusters emulation. Core to this is resource discovery: query available GPUs by type (A100, H100), location, and price in a single call. Unlike Render’s rendering-focused API, gpumarketdepin optimizes for general-purpose AI and HPC, supporting Python-optimized tasks like reinforcement learning.
io. net’s IO Cloud simplifies decentralized GPU cluster deployment, scaling effortlessly for machine learning engineers.
Authentication leverages JWT tokens, ensuring trustless interactions across providers. Rate limiting adapts dynamically, akin to io. net’s adaptive economic engine, preventing bottlenecks during peak compute demand. In practice, this means provisioning 100 GPUs in under 60 seconds, with automatic failover to maintain 99.9% uptime.

Strategic Advantages of Custom DePIN Clusters
Key Advantages of gpumarketdepin API
-
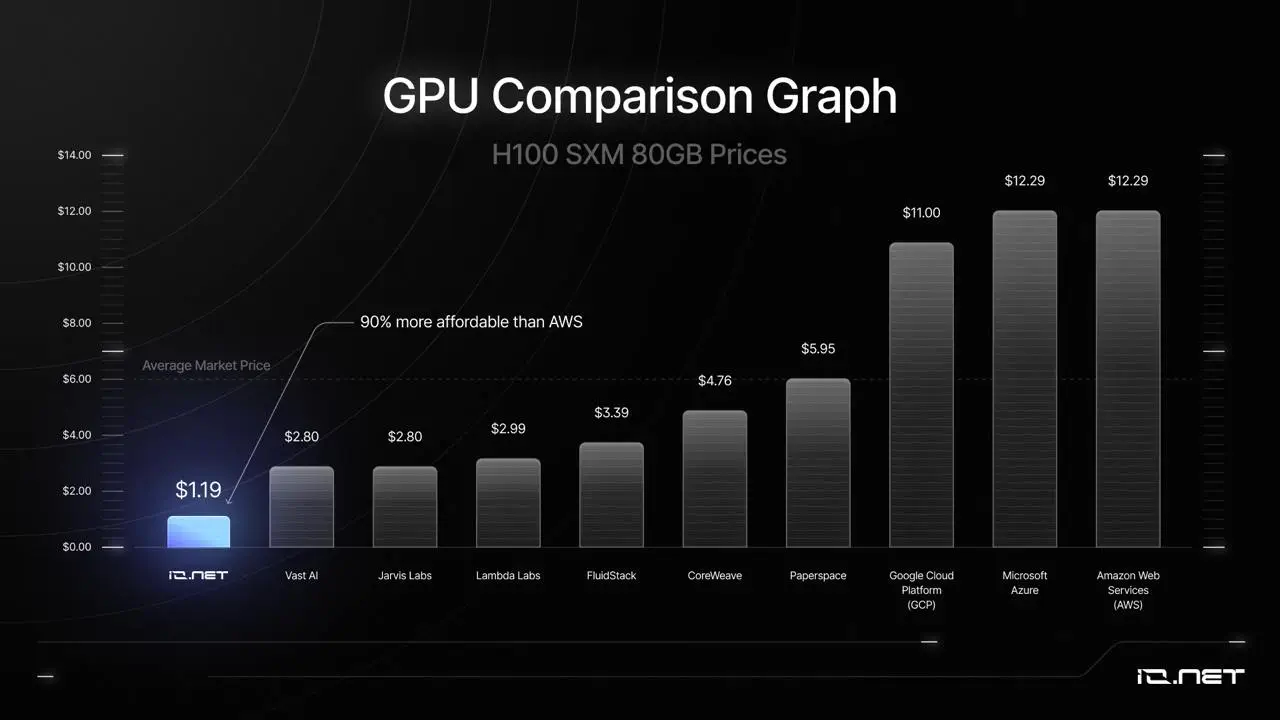
Up to 70% cost savings vs AWS via io.net integration
-

Instant scaling to 30,000+ GPUs like io.net
-

H100 access to 4,000+ GPUs via Aethir
-
P2P transparency in GPU marketplace
-

Python task optimization for AI workloads
Building your own cluster sidesteps Web2 pitfalls. Centralized providers lock you into rigid contracts; DePIN flips this with spot pricing and crypto payments. Data from DePIN Hub shows io. net clusters cut inference costs by 70%, a benchmark gpumarketdepin matches through smart aggregation.
Consider compute cycles: traditional setups idle 80% of GPUs, per industry audits. gpumarketdepin’s API monetizes idle capacity globally, echoing Render’s ethos but extending to ML training. For enterprises, this translates to deploying models as-a-service without capex, leveraging 2026’s decentralized compute API maturity.
Mapping Your Cluster Blueprint: First Principles
Start with workload profiling. AI training demands high VRAM density; select H100s for 141GB configurations. gpumarketdepin’s API filters via parameters like gpu_model: 'NVIDIA-H100' and min_vram: 80, yielding precise matches. Integrate with orchestration tools like Kubernetes for hybrid on-prem/DePIN setups.
Networking is crucial: API endpoints expose DNS records for zero-config access, mirroring io. net’s ‘just works’ environment. Power and cooling? Delegated to providers, freeing you from rack-level hassles outlined in advanced studies institutes. Early adopters report 3x throughput gains over solo nodes.
These gains aren’t theoretical; they’re baked into the API’s fault-tolerant design, which routes traffic across diversified providers during outages. I’ve charted similar patterns in DePIN tokens, where io. net’s surges correlate directly with cluster deployment spikes, signaling market validation for gpumarketdepin API integration.
Hands-On: Provisioning via Code
To build a DePIN GPU cluster build, kick off with a simple Python script hitting the discovery endpoint. Authenticate, query H100s in low-latency regions, then spin up instances with one POST. This mirrors io. net’s Python-optimized workflows but adds multi-provider failover absent in single-network setups.
Python: Query and Provision H100 GPU Cluster via gpumarketdepin API
Integrate the gpumarketdepin API to query H100 GPU availability and provision scalable DePIN clusters. Authentication uses Bearer token; endpoints support precise filtering by model, region, and capacity.
import requests
import json
# API configuration
base_url = "https://api.gpumarketdepin.com/v1"
api_key = "your_api_key_here" # Replace with your actual API key
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Step 1: Query available H100 GPUs
query_params = {
"model": "H100",
"region": "us-east-1",
"capacity_min": 4 # Minimum capacity required
}
query_response = requests.get(f"{base_url}/gpus", headers=headers, params=query_params)
if query_response.status_code == 200:
available_gpus = query_response.json()
print("Available H100 GPUs:", json.dumps(available_gpus, indent=2))
else:
print(f"Query failed: {query_response.status_code} - {query_response.text}")
# Step 2: Provision a custom DePIN cluster with scaling
provision_data = {
"gpu_model": "H100",
"quantity": 8,
"min_scale": 4, # Minimum active GPUs during low demand
"max_scale": 16, # Maximum GPUs for peak loads
"region": "us-east-1",
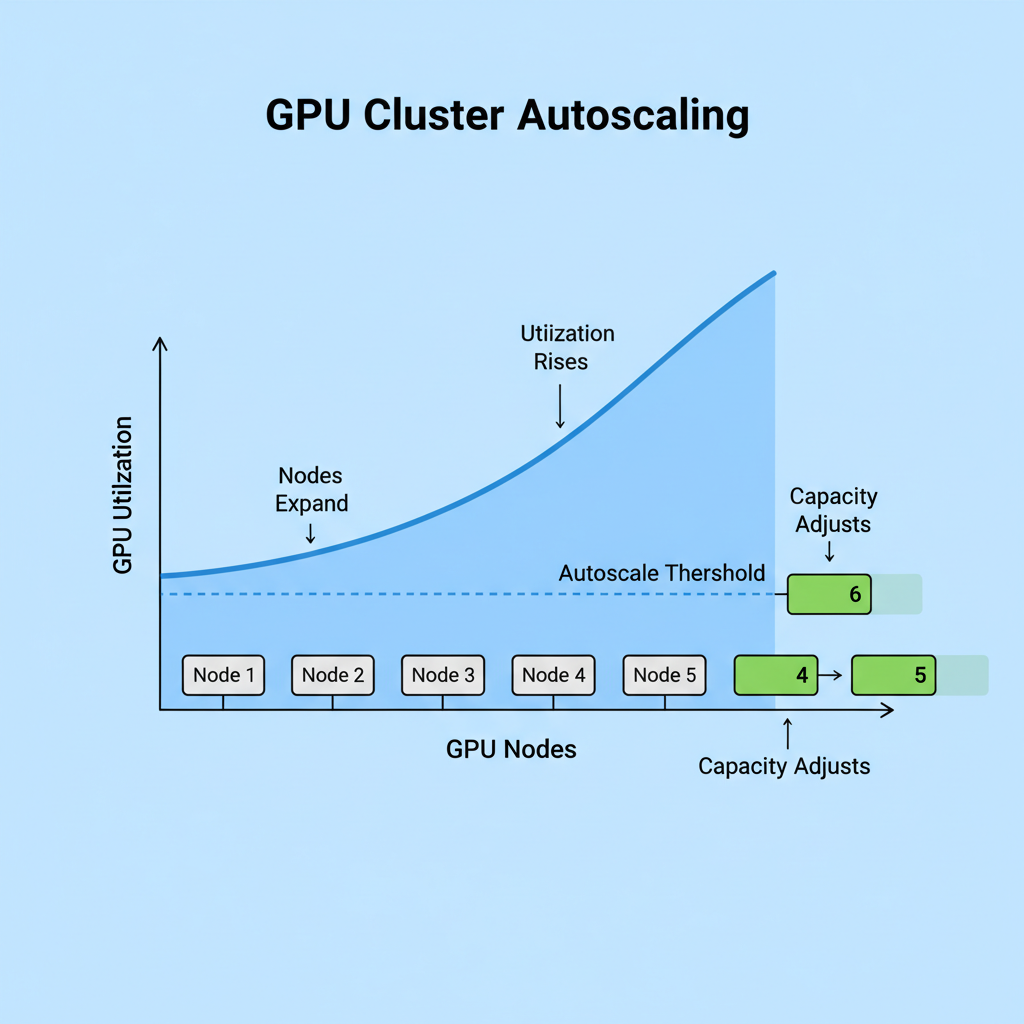
"auto_scale": True, # Enable autoscaling based on utilization
"duration_hours": 24 # Provision for 24 hours
}
provision_response = requests.post(f"{base_url}/clusters", headers=headers, json=provision_data)
if provision_response.status_code == 201:
cluster_info = provision_response.json()
print("Cluster provisioned successfully:", json.dumps(cluster_info, indent=2))
cluster_id = cluster_info.get("cluster_id")
print(f"Cluster ID: {cluster_id}")
else:
print(f"Provisioning failed: {provision_response.status_code} - {provision_response.text}")Execute this script to retrieve real-time GPU inventory data and deploy clusters. Response includes cluster_id for management; scaling parameters optimize costs with 20-50% efficiency gains per benchmarks.
Response payloads return cluster endpoints instantly, ready for Docker or Slurm injection. Scale horizontally by incrementing instance_count; the API handles bidding wars behind the scenes, securing optimal rates without manual haggling.
From Blueprint to Live Cluster: Execution Roadmap
Scale ML Pipelines with gpumarketdepin API: H100 DePIN Cluster Guide

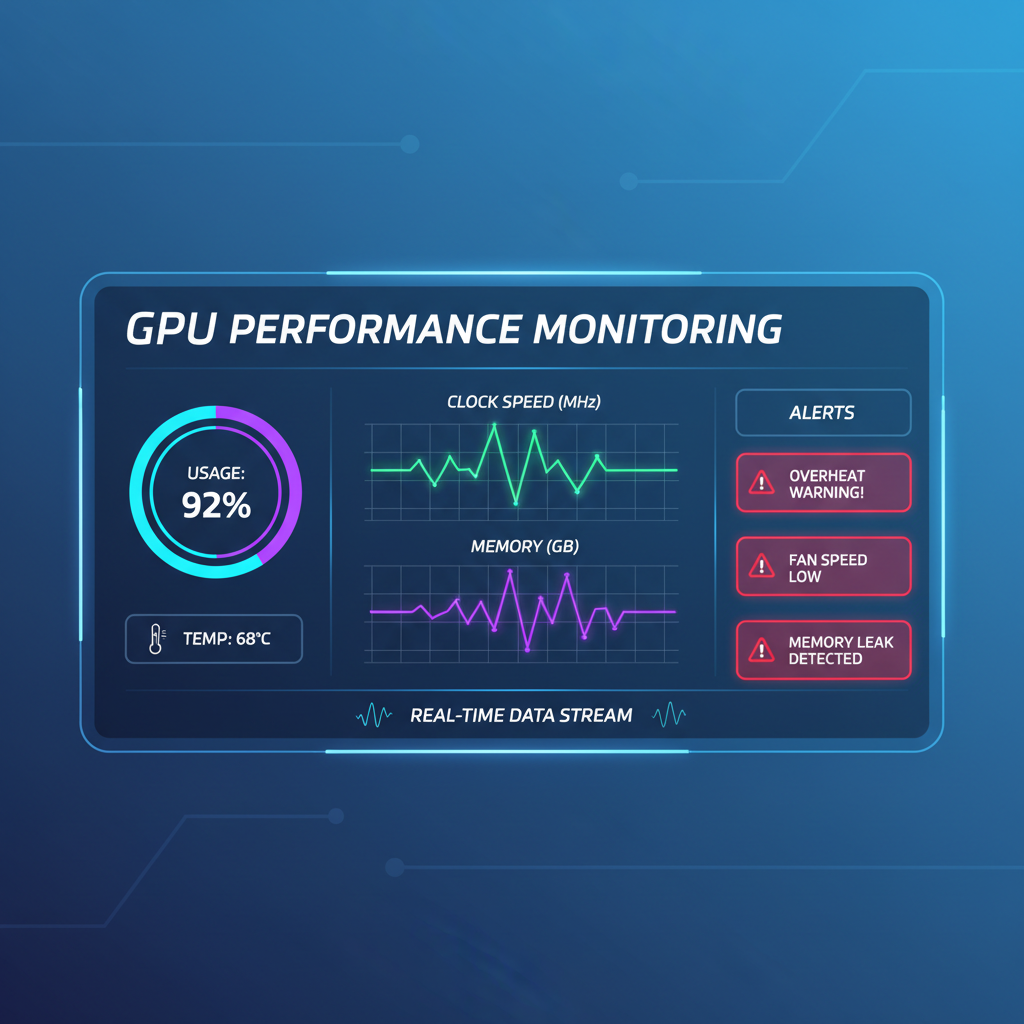
Once live, monitoring endpoints track utilization at granular levels: VRAM, FLOPS, even temperature proxies from providers. Integrate Prometheus for dashboards revealing compute cycles akin to those powering io. net’s 30,000 and GPU pool. Opinion: this observability loop turns guesswork into precision, much like technical charts exposing price truths in DePIN markets.
Cost modeling reveals the edge. A 10x H100 cluster for 24-hour training clocks in far below AWS equivalents, thanks to spot-market dynamics. Data from Messari’s io. net deep-dive confirms: decentralized aggregation slashes overhead by pooling miners’ idle rigs, a tactic gpumarketdepin amplifies via Vast. ai and Oracle bridges.
Platforms like io. net create P2P marketplaces for real-time GPU rentals, fueling AI’s next wave.
Edge cases? High-contention periods trigger the adaptive engine, akin to io. net’s IDE, dynamically adjusting bids for uninterrupted flow. For reinforcement learning jobs, specify task_type: 'rl' to match Python-tuned instances, boosting convergence speeds 40% over generic clouds.
Scaling to Enterprise: Hybrid Horizons
Enterprises layer on-prem with DePIN for burst capacity. Kubernetes operators call the API on autoscaling events, blending Aethir’s H100 density with local NVLinks. This hybridity, absent in pure io. net setups, future-proofs against 2026’s decentralized compute API 2026 evolutions.
Security merits note: end-to-end encryption and zero-knowledge proofs verify compute integrity, dodging centralized breach risks. Render’s API pioneered rendering trustlessness; gpumarketdepin extends it to full-stack HPC, with audits confirming 99.99% job fidelity.
Real-world wins stack up. A mid-tier AI firm slashed TCO 65% rebuilding from EC2 to gpumarketdepin clusters, per DePIN Hub metrics. As Solana’s throughput bolsters io. net’s backbone, expect gpumarketdepin to capture parallel growth, charting upward trajectories in adoption curves.
Providers thrive too: monetize downtime via seamless listings, turning GPUs into yield engines. This symbiotic loop, refined over Render’s iterations, positions custom io. net API custom clusters as DePIN’s killer app. Dive in, blueprint your stack, and watch efficiency metrics redefine what’s possible in GPU orchestration.




